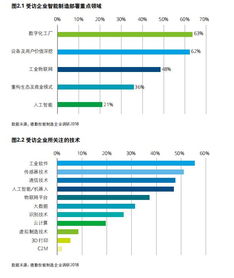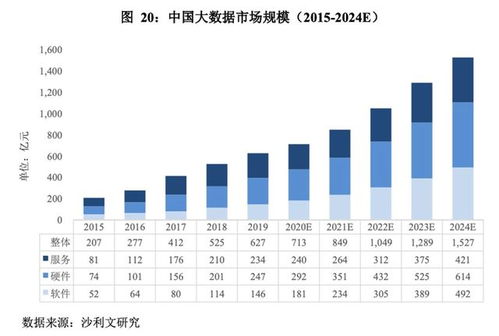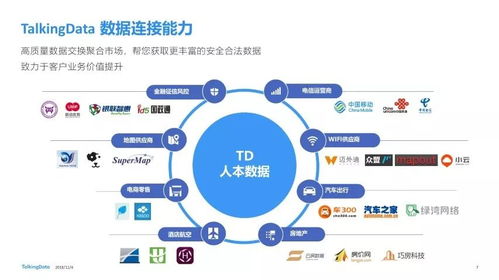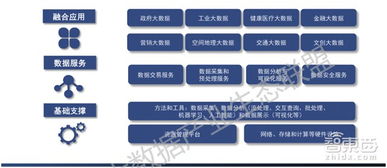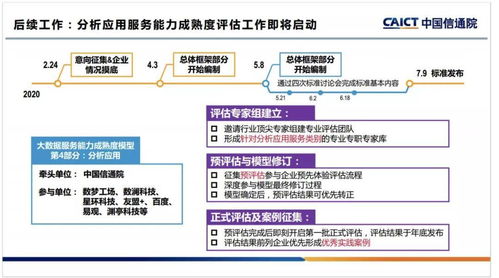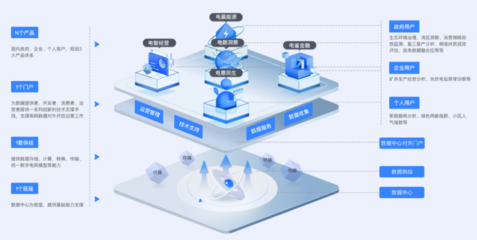
在當今全球性的數字化轉型浪潮中,企業若想提升競爭力、優化運營效率并創新商業模式,軟件開發已成為關鍵引擎,而大數據技術則是驅動這一引擎的核心燃料。大數據技術不再僅僅是海量數據的存儲與分析工具,它已深度融入軟件開發的各個階段,從需求洞察、架構設計到產品迭代與智能運維,全方位重塑了軟件的生命周期。其應用主要體現在以下幾個層面:
一、 數據驅動的需求分析與產品設計
傳統的需求分析往往依賴于市場調研、用戶訪談等主觀性較強的方法。如今,企業可以利用大數據技術,對內部業務系統(如ERP、CRM)、外部社交媒體、物聯網設備、用戶行為日志等產生的海量、多源數據進行實時或離線分析。通過數據挖掘與機器學習算法,軟件開發團隊能夠更精準地識別潛在的用戶痛點、預測市場趨勢、描繪精細化的用戶畫像。例如,通過分析電商平臺的用戶點擊流、購買歷史和搜索關鍵詞,可以量化不同功能對轉化率的影響,從而在軟件新版本中優先開發高價值特性,實現從“經驗驅動”到“數據驅動”的產品決策。
二、 智能與個性化的功能實現
大數據技術是構建智能化軟件功能的基礎。在開發過程中,集成機器學習框架(如TensorFlow、PyTorch)和實時數據處理引擎(如Apache Flink、Spark Streaming),使軟件能夠具備推薦、預測、識別等高級能力。例如:
- 個性化推薦系統:基于協同過濾、內容分析等算法,為每位用戶提供定制化的內容、商品或服務推薦,顯著提升用戶體驗與商業價值。
- 預測性維護:在工業軟件或物聯網應用中,通過分析設備傳感器歷史數據,建立模型預測故障概率,實現從“事后維修”到“事前預防”的轉變。
- 自然語言處理與圖像識別:集成相關模型,使軟件能夠理解文本語義、識別圖像內容,賦能智能客服、內容審核、醫療輔助診斷等場景。
三、 現代化軟件架構與數據處理流水線
為應對大數據處理的挑戰,軟件開發在架構層面發生了深刻變革。微服務架構的流行,使得各個服務可以獨立處理與其相關的數據,并通過API進行通信,提高了系統的可擴展性和靈活性。開發團隊需要構建高效、可靠的數據流水線(Data Pipeline),這通常涉及:
- 數據采集與集成:使用Kafka、Flume等工具實現多源數據的實時采集與流式接入。
- 數據存儲:根據數據特性和訪問模式,組合使用關系型數據庫、NoSQL數據庫(如HBase、MongoDB)以及分布式文件系統(如HDFS)或數據湖(如基于云存儲的數據湖)。
- 計算與處理:利用Hadoop MapReduce進行批量處理,或利用Spark進行內存計算以實現更快的迭代分析,利用Flink處理復雜的實時流計算任務。
- 數據服務化:將處理后的數據通過API或數據服務平臺暴露給前端應用或其他業務系統,形成數據閉環。
四、 基于數據的持續測試、運維與優化
在軟件發布后,大數據技術的作用并未終止。A/B測試平臺通過實時收集和分析不同用戶群組的行為數據,科學評估新功能或界面改動的效果。在運維側,監控系統收集服務器性能指標、應用日志和用戶端性能數據,通過時序數據庫和流處理技術進行實時分析,實現異常檢測、根因定位和性能瓶頸分析,推動智能運維(AIOps)。通過持續分析生產環境中的用戶行為數據,可以形成反饋循環,為下一輪的產品迭代提供直接依據,實現軟件的持續優化與增長。
五、 安全保障與合規性管理
在數據價值凸顯的安全與合規成為軟件開發不可忽視的一環。大數據技術可用于構建安全分析平臺,通過分析網絡流量、用戶訪問日志和操作行為,利用機器學習模型檢測異常模式、識別潛在的攻擊或內部威脅。在數據治理方面,通過元數據管理、數據血緣追蹤和質量監控,確保在軟件開發和使用過程中,數據的準確性、一致性和合規性(如滿足GDPR等數據保護法規要求)。
而言,在企業數字化轉型的背景下,大數據技術與軟件開發的融合已從“可選”變為“必選”。它貫穿于軟件價值創造的全過程,不僅賦能軟件變得更智能、更個性化,也深刻改變了軟件的構建、交付和運營方式。成功的關鍵在于企業需要建立跨職能的數據團隊(包括數據工程師、數據科學家和軟件開發工程師),培養數據文化,并選擇與業務目標相匹配的技術棧,從而將數據資產有效轉化為驅動業務增長的軟件創新能力。